The Google File System,a scalable distributed file system for large distributed data-intensive applications。本文翻译6.824的gfs概述
为什么要读这篇论文
- 分布式存储是很关键的抽象
- 定义接口、语义应该是怎么样的
- 工作原理
- 6.824课程的主题:并发性能、容错、副本、一致性
- 好系统的论文 - 真实世界应用访问网络的细节
为什么分布式存储很困难?
high performance -> shard data over many servers many servers -> constant faults fault tolerance -> replication replication -> potential inconsistencies better consistency -> low performance
一致性应该是怎样的?
理想模型:表现和单个服务的行为一样 服务用的磁盘存储 服务一次执行一条客户端的操作(即使是并发) 读操作应该能观察到之前的写操作(即使服务奔溃重启) 因此: 假设C1、C2并发写,那么C3、C4将读到什么?
1 | |
要么1,要么2,反正值是一样的。 这就是”强”一致性模型。 但单个服务器容错差劲
为了容错使用副本,增大强一致性的复杂度
设想一个简单但不可行的副本机制: - 两个副本,S1、S2 - 客户端,对写请求,同时发给两台 - 客户端,对读请求,请求其中一台
那么,对上述的例子,C1、C2的写请求如果以不同顺序到达两台服务器, 那么C3、C4分别读S1、S2的值就不一样了,这就不是强一致性了。
要求更高的一致性需要副本间的同步,而这会变慢!因此,要在性能和一致性之间权衡。
GFS的背景
- Google的服务,需要通用的大而快的存储系统, 比如MapReduce、crawler/indexer、log storage/analysis、YouTube
- Global(超过一个数据中心):任何客户端可以访问任何服务/磁盘
- 每个文件在服务/磁盘,自动分片
- 提高并行度
- 提高空间利用率
- 自动的故障恢复
- 一次部署,只一个数据中心
- 只对Google应用和用户
- 为了有序的访问大文件:读或写;做对比,并不是像低延迟数据库小操作那样
在2003年,为什么论文被SOSP接收了?
- 并非因为分布式、分片、容错这些基础的想法,因为在此前就有了
- 巨大的可伸缩性
- 工业界的生产实践
- 弱一致性的成功应用
- 单点master的成功应用
系统概述
- clients客户端(库、RPC)
- 每个文件分割成多个独立的64M的chunks
- chunk servers,每个chunk存在3个chunk server上
- 每个文件的chunks,被分布在chunnk servers上 为了提供对大文件的并发读、写,如MapReduce
- 单点master,和master的副本
- 划分功能:master负责naming(定位文件),chunk servers负责读写数据
master的状态
- in RAM(为了速度,也不大):
- file name -> array of chunk handles (nv)
- chunk handle -> version # (nv) list of chunkservers (v) primary (v) lease time (v)
- on disk:
- log
- checkpoint
nv: 非易失,v: 易失
为什么用log?checkpoint?
为什么用大的chunks?
系统架构
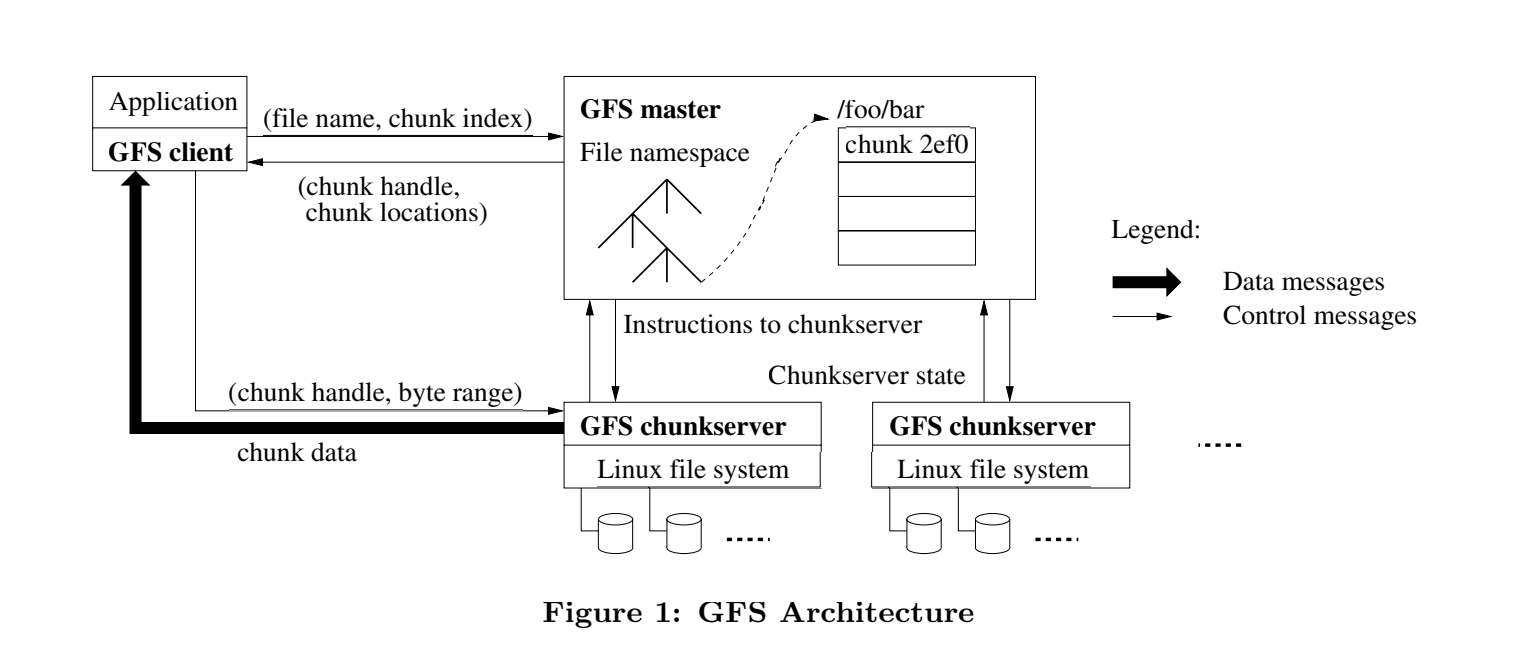
- client请求master,发送filename、offset
- master找到chunkhandle
- master响应chunkserver列表(chunk是最新的那些)
- client缓存handle和chunkserver
- client请求最近的chunkserver,发送chunkhandle、offset
- chunkserver读取文件,返回数据
master如何知道chunkserver上我们要的chunk?
写流程
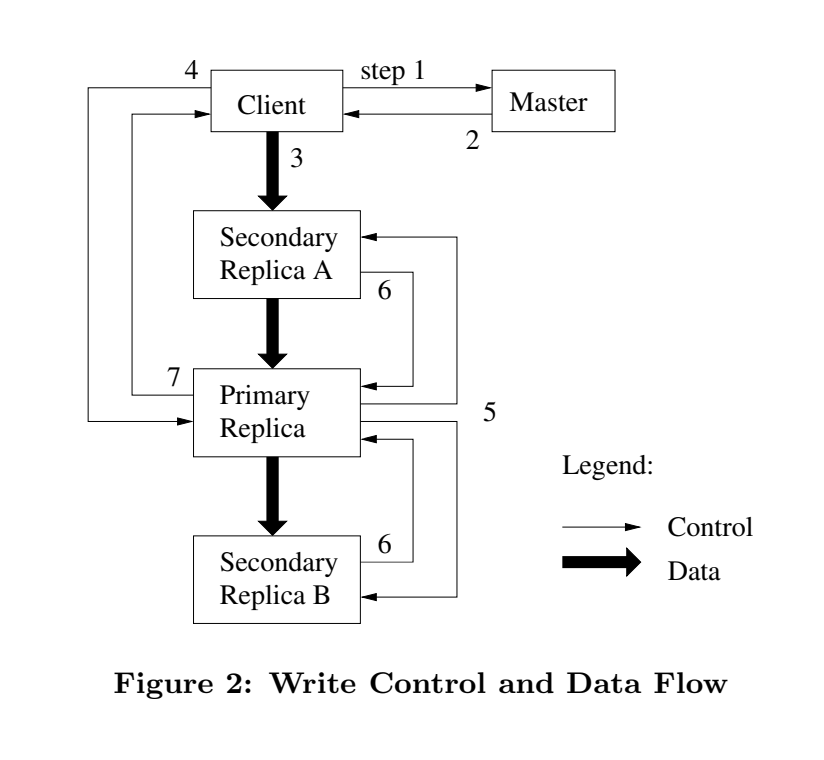
步骤
- client向master请求那个chunkserver是chunk的的当前lease(租约), 以及chunk副本的chunkserver
- master返回primary(当前租约的chunkserver)和secondary(副本的chunkserver), 并且client讲缓存起来。再请求master的时,应该是primary不持有当前的lease
- client把数据推到各个chunkserver,通过底层的网络拓扑的优化,提高传输效率。
- 所有chunkserver都确认收到数据后,向primary发写请求,将之前推送的数据进行写入。 于是,primary进行了写操作。有多个写操作,那么primary的对这些写操作顺序是确定的
- primary再把写请求推给secondary,这样,secondary也用和primary相同的顺序进行写操作
- 所有secondary回应primary已经完成操作
- primary响应client,只要任何secondary返回失败,那么响应error, 也就有可能部分secondary数据已经不一致了。error时,client要在放弃前可以重试几遍(第3步-第7步)
所以会遇到很多问题:
- 比如第一次写B,由于s2失败了,导致客户端重试,那么有可能这样: primary :ABCB secondary1:ABCB secondary2:A CB 注:这里是要空出来的,他们要在同一位置append
GFS对客户端的一致性保证?
需要客户端自行解决一致性问题,比如对于顺序敏感的操作,由当个客户端发起请求。 对数据设有晒重的标志,比如哈希值
思考
如果primary告诉客户端append操作成功,那么接下来的任何读请求,应该都可以看到这一结果。
那么GFS是如何满足这一性质的呢? 观察一系列失败情况的处理:crash, crash+reboot, crash+replacement, message loss, partition
- 如果发起写操作的client挂了?
- 如果如果client从缓存取的primary已经失效?
- 如果如果读操作,client从缓存读的secondary已失效?
- master要是crash+reboot,会遗失哪些文件?会遗失chunkservers关联的chunk吗?
- 两台clients同时写,会彼此覆盖记录吗?
- 如果一台secondary从没执行primary的写操作,那么应对client的读请求要怎么做?
- primary推写请求给secondary前crash,会怎样?某个secondary可以漏掉这个写请求, 当选新的primary吗?
- 如果chunkserverS4,离线很久,其中的chunk版本很老了,
此时primary和在线的chunkserver都crash,S4恢复工作时,master会不会挑S4做primary?
是否有更好的办法解决旧版本的问题?
master需要持久化chunk的版本
- 如果某个secondary总是失败,primary怎么办?(比如磁盘空间不足,磁盘坏了), 是否primary应该把这台secondary移除secondaries列表?然后返回给客户端操作成功? 还是维持原来的操作,继续推,继续失败?
- 要是primary S1响应client的请求时,master和S1的网络断了?”网络分裂”
master会挑新primary吗?会不会有两个primaries?
那就可能一个primary写请求,一个primary读请求,破坏了数据一致性?
“split brain”脑裂。
为了避免脑裂,master应该要等持有lease的primary过期,那么lease要设一个可接受的等待时间
- 如果其中一个primary服务客户端写请求时,租约到期了, master挑新的primary,新primary会有被之前primary更新的数据吗?
- master fails?还有什么办法知道chunk的信息,比如chunk的版本号、priamry、租约时间
- master挂了,怎么检测,谁检测?是否有替代方案? master的副本ping master,没响应就接管,可行吗?
- 整栋楼停电会怎样?电力恢复后,重启,又会怎样?
- 如果master想增加chunk的副本数(可能副本太少了), 怎样保证增加chunk的副本时,不会错过正在发生的写操作?毕竟此时还不是secondary
- GFS有可能违反一致性保证吗?比如,写成功了,但后续的读请求观察不到
- 所有master及副本永久丢失状态(比如磁盘坏了),这可能更糟,直接就没响应,而不是数据问题了
- 包含这个chunk的所有的chunk server丢失磁盘数据。
- 服务器数据未同步,租约机制失效,可能有多个primaries,那么可能写一个,读一个
GFS是否允许client观察到一些奇怪的行为?
- 所有clients看到的文件内容一致?
- 是否一些client能看到,一些client看不到?
- 连续读两次,结果是否一样?
- 所有clinets看到的写记录,顺序都一样?
这些奇怪的现象,对应用有什么影响?比如MapReduce?
没有这些奇怪现象,会带来什么 - 严格的一致性?
比如所有client看到相同的文件内容 难以描述,可以用案例思考:
- primary要检测到client请求的副本,或者说client不该请求副本
- 所有secondaries要么都写,要么都不写。可能会有中间状态,直到有确定的结果。但这个过程不该暴露出结果。
- 如果primary crash,一些副本可能错过最新的操作,新primary应该同步给他们
- 避免client读到ex-secondary,或者说client的读也要通过primary,或者说secondary也要有租约机制
性能
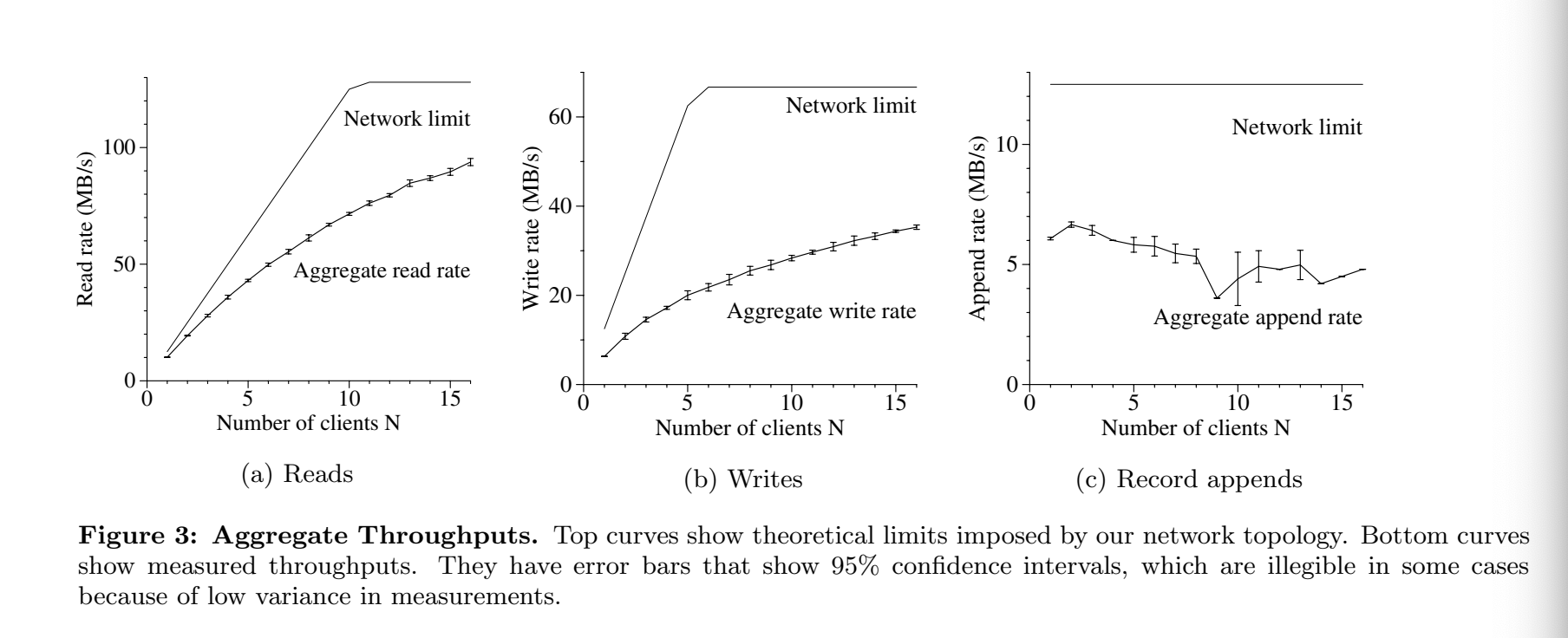
读操作的吞吐量: 94MB/sec for 16 chunkservers, 即一个chunkserver,6MB/sec,good? 一个磁盘顺序访问的吞吐量大概30MB/s 一个NIC大概10MB/s 差不多就是网络饱和的状态(内网交换机) So: individual server performance is low but scalability is good which is more important?
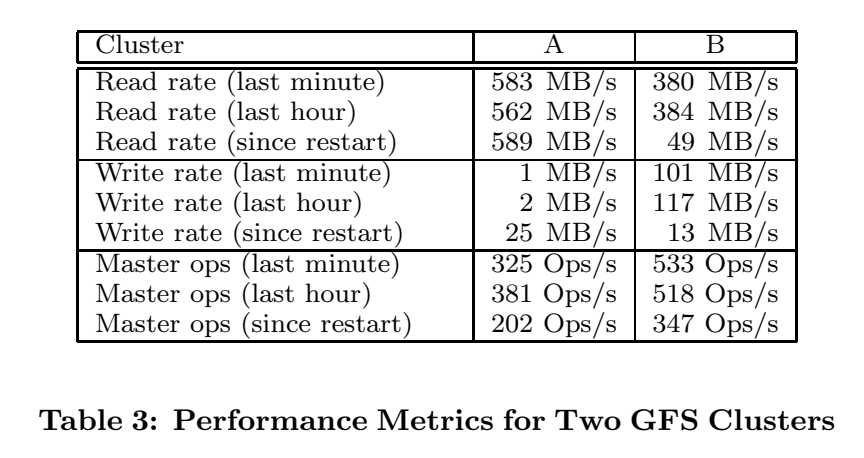
GFS对读操作500MB/sec,写不同文件的操作比可能的最大值低。 作者指出了网络攻击(没有细节) 并发对单文件写 受限于存储最新chunk的server 15年后会怎么样,很难预测,磁盘速度将有多快?
GFS一致性定义
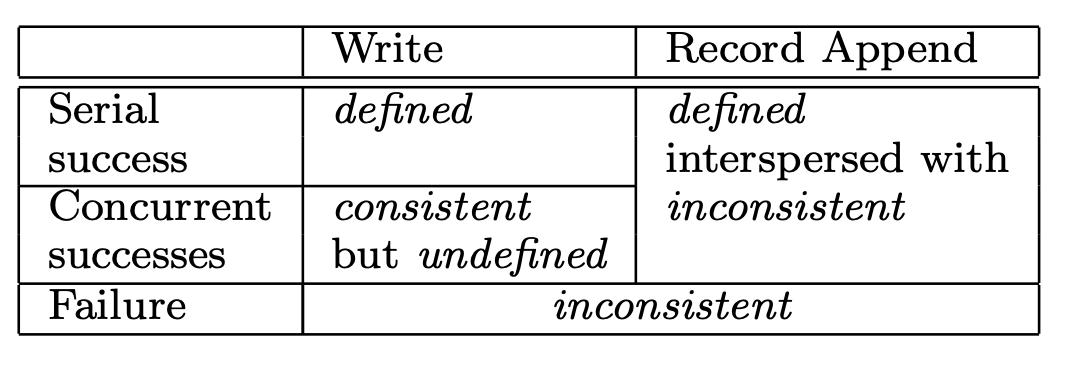
write操作是需要指定offset的。 并发条件下,两个写的区域如果有重合,也就是写的顺序会影响结果。 那么发出写操作的两个clients,即使收到成功,但无法确认写的结果的。所以是consistent but undefined。 相反,串行操作,client是可以确定写成功的结果,是defined。
append操作,client不需要指定offset,由primary确定append的位置,最后返回给client, 不会发生两个append相互覆盖的情况,即使出现了,那么直接告诉client失败,再重试, 直到所有chunkserver都在同一个offset进行append,所以是defined,由于操作可能试了几遍才成功, 那么有部分secondary可能已经写过了,所以是interspersed with inconsistent
值得思考的
- 如何更好得支持小文件?
- 如何更好得支持数十亿文件?
- GFS作为wide-area的文件系统吗? 在不同城市存放副本? 全部副本在一个数据中心,容错度不高
- GFS故障恢复要多久? primary、secondary? master?
- GFS如何应对处理慢的chunkservers
GFS工程师回顾
http://queue.acm.org/detail.cfm?id=1594206
- 文件计数是最大的问题 文件数量增长了1000x(Table 2) master的RAM不适用了 master的GC,扫描文件太慢了
- 1000多的clients请求master,CPU负载占用大
- 应用必须遵循GFS的设计语义和限制
- master的故障恢复需要人工接入,数十分钟
- BigTable,可以用在小而多的文件存储问题。Colossus将master分片到多个master上
课程总结
- 案例学习:性能、容错、一致性
- 好的想法:
- 通用的全局文件系统
- 分离naming(master)和存储(chunkserver)
- 文件分片,提高并发吞吐量
- 大文件和大chunk,对比多的小文件,减少了必要的存储开支
- primary定义多个的写操作顺序
- lease防止脑裂
- 不够好:
- 单点master性能
- chunkserver对小文件效率不高
- 缺少master故障自动恢复
- 可能一致性的保障太弱了