6.824 2020 Lecture 15: Spark
Resilient Distributed Datasets(弹性分布式数据集): A Fault-Tolerant Abstraction for In-Memory Cluster Computing Zaharia et al., NSDI 2012
为什么要研究Spark?
- 广泛用于数据中心的计算
- 生成MapReduce任务进数据流
- 比MapReduce更好的支持迭代的应用
- 成功的研究:ACM的博士论文奖
三个主要的话题
- 编程模型
- 执行策略
- 容错
先来看page-rank 来自Spark源码库的SparkPageRank.scala,代码Sec3.2.2
1 | |
page-rank的输入每个link一行,来自网页爬虫 from-url to-url 输出是巨大的!
page-rank的输出时每个页面的”importance”
- 是基于其他”importance”的网页是否指向这个网页
- 真实的模型计算了人们可能访问网页的概率
- 用户模型:
- 从当前页面,有85%的可能点击一个具体的链接
- 15%的可能随机访问一个页面
page-rank算法
- 迭代的,本质是模拟用户多轮的点击链接
- 权重(概率)逐渐收敛
- page-rank算法,使用MapReduce实现则不方便、慢
比如输入文件”in”:
1 | |
我们在Spark中运行page-rank算法(本地机器,非集群):
1 | |
通过看结果,u1是最重要的(important)页面
在Scala交互行中,运行page-rank的代码
1 | |
到最后一个collect(), 代码只是创建了一个线状图,还没开始处理数据
线状图长什么样?
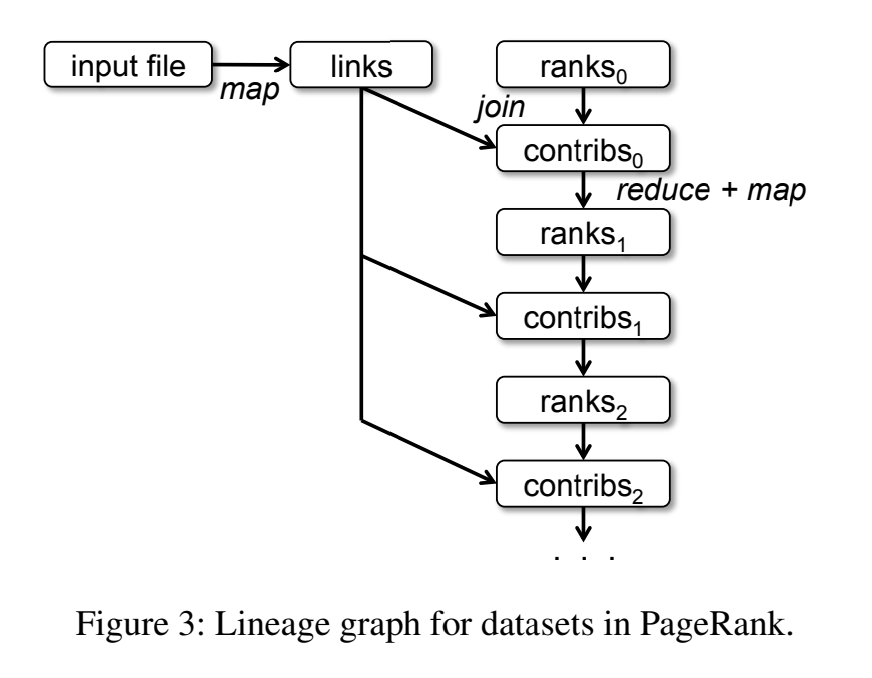
这就是描述转换步骤的图——数据量图。完整的计算步骤。 注意,虽然代码有循环,但是图里是没有循环的。 每次迭代都是新的ranks/contribs
对于多不的计算,编程模型比MapReduce更加方便
scala代码运行在”驱动”(driver)机器上
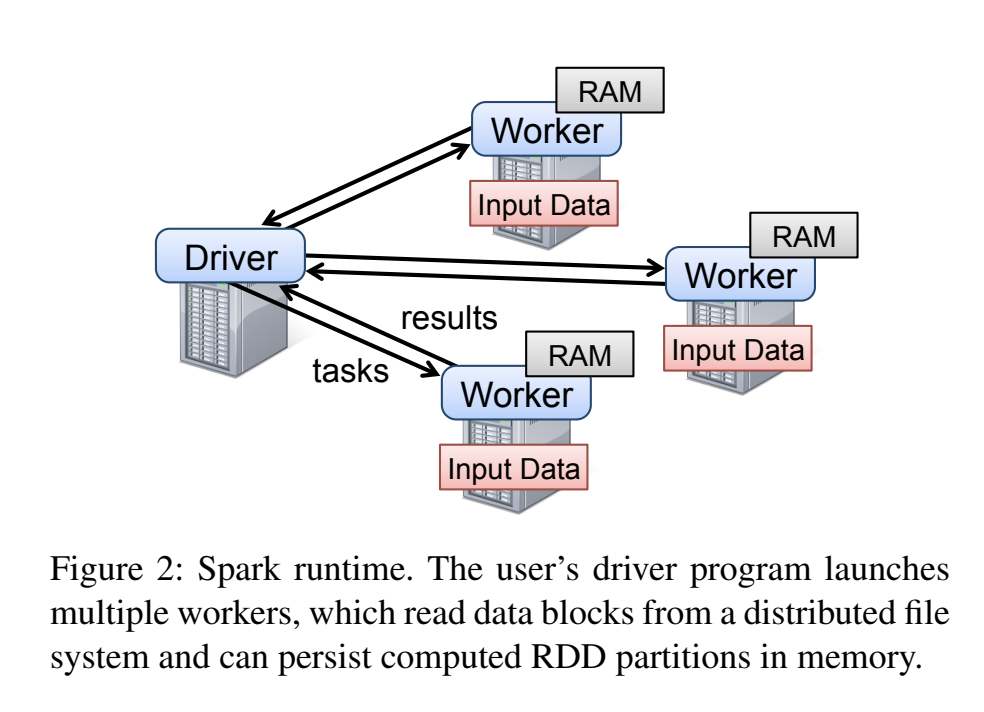
- “驱动”构建了线状图
- “驱动”编译java字节码,发生给worker机器
- “驱动”管理执行过程和数据移动
执行过程是怎样的?
[diagram: driver, partitioned input file, workers]
- 从HDFS(类似GFS)获取输入
- 输入数据文件已经被划分到了多个存储服务器,第一块有钱100w行,之类的
- 分区比机器数多,为了负载均衡
- 每个worker机器拿走一个分区,顺序地应用线性图
- 当计算的各分区是独立的:1. 读取后不需要机器间通信,2. worker对输入流应用一连串的变换
为什么这比MapReduce更有效?
数据直接从一个变化到下一个变换,MapReduce需要多重的map+reduce,特别是耗时的GFS的存储和再读取
那distinct()? groupByKey()? join()? reduceByKey()? 这些操作需要所有分区的数据,而非一个分区,因为所有的记录必须全部一起考虑,这就是论文中说的”wide”(宽)依赖(相对于”narrow”(窄))
宽依赖要如何实现?
[diagram]
- 很想MapReduce的中间输出
- driver知道宽依赖在哪个环节,比如page-rank的map()和distinct()z之间
- 数据到一个新分区前要混合,比如把所有指定的key都放到一起
- 上一个变换以后:
- 通过混合规则分割输出(特别是一些key)
- 放进内存的buckets中,每个下游分区对应一个
- 在进行下一个的变换前
(等待是一部完成——由driver管理)
- 每个worker从自己的bucket,抓取上一个worker数据
- 现在数据已经通过不同的key进行分区的
宽依赖的成本很高!因为所有数据通过网络传输,还有阻塞(等待上一步全部完成)
要是数据重复使用? 比如links4? 默认的,可以重新计算,比如重新从输入文件读取。 persist() and cache()可以将links的数据存在内存中以便重复使用
重复使用内存中persist的数据也是相对于MapReduce的一大优点
spark可以基于全部线状图做优化
- 记录流,一个时间一个记录,通过窄变换
- 增加了局部性,对CPU数据缓存有利
- 避免了把分区的数据数据一次性加载进内存
- 注意一些操作是没必要的,因为之前的数据已经以同样的方式做了分区,比如links4.join(ranks)
容错怎么样? 要是一台机器挂了?
- 它的内存和计算过程会丢失
- 驱动会重新把挂的机器执行的分区交给其他机器做变换
- 通常每个分区都负责多个分区,所以负载可以分散,因此从新计算是非常快的
- 对于窄依赖,只要把丢失的分区重新执行即可
要是执行宽依赖时失败了?
- 重新计算失败的分区,需要所有的分区
- 所以所有的分区要重头开始执行
- spark支持对HDFS的checkpoints,driver只要从上一个checkpoint开始计算
- 对于page-rank,可能每10次迭代做一次checkpoint
有什么局限性?
- 为批量数据设计的批处理
- 所以的记录都是同一种处理方式
- 变换是函数式的,即输入到输出:不能原地修改数据
总结:
- spark提升MapReduce的表达能力和性能
- 给出了完整数据量视角的框架,非常有用:性能优化、故障恢复
- 性能的关键是什么:1. 变换的数据留着了内存,而不是写入GFS然后在读;2. 重复利用内存中的数据
- spark非常成功,广泛应用