6.824 2020 Lecture 17: Causal Consistency, COPS
Lloyd et al, Don’t Settle for Eventual: Scalable Causal Consistency for Wide-Area Storage with COPS, SOSP 2011.
配置:大web网站的地理复制
[ 3 datacenters, users, web servers, sharded storage servers ]
- 多数据中心
- 每个数据中心是完整数据的拷贝
- 读本地——快速的一般情况
- 写操作怎么样?
- 一致性怎么样?
我们已经看了两种地理复制的方案
- Spanner
- 写操作涉及Paxos,可能还有两阶段提交
- Paxos写需要大多数票,必须等待远程网站
- 没有网站可以独立地写
- 但是有读事务、一致性、非常快
- Facebook/Memcache
- 写必须到primary的Mysql
- 也就是,非primary不能独立的写
- 但是读一定非常快(每个mc 100w/s)
我们可以让系统,在任何数据中心都可以写吗? 这样写就不用和其他数据中心通信和等待。 将有助于容错,性能,鲁棒性与慢速WAN 这些本地的读和写就是真正目标 一致性模型是第二考虑的, 为了本地读/写设计,我们必须做些相匹配的问题
稻草人1号
- 三个数据中心,
- 每个数据中心都是一组分片,
- client读/写都只和本地通信
- 每个分片吧写数据推送给其他数据中心,分片到分片,异步进行
- 增加了并行度
- 这个设计偏向读,写操作是完全本地的, 读操作检查其他的数据中心和大多数(即重叠了),像Dynamo/Cassandra
稻草人1号是“最终一致性”(eventually consistent)设计
- clients可能看到的更新顺序不一样
- 如果很长时间没有写操作,所有clients看到同样的数据 这是很宽松的条件,有很多实现方式,性能也很不错, 已使用的系统,比如Dynamo and Cassandra,但是对应用编程人员需要一定的技巧
应用代码案例——照片管理
1 | |
C2能看到什么?C4能看到什么?
应用代码会看到非直觉的行为——“幻觉”(anomalies) 并不是不对,因为并没有这种承诺,它可能变成这样的系统:
- 可能每个值需要包含版本
- 可能需要等待逾期的数据(照片)出现
但是我们希望更加直觉,更易于变成的行为
重要的一面:怎样知道那个写是最新的? 多个远程数据中心可能写相同的值,每个数据中心最后都要选择相同的值,因为要达到最终一致性
为什么每次put时,不使用时间戳作为版本号呢? 当收到client的put,本地分片赋值v#=time 远程数据中心接收put(k, _, v#) 如果v#比当前数据的版本号大,就替换,否则忽略
使用时间戳大多时候是可以的。
但是,要是不同数据中心,put(k)的时间一样呢?赋值v#的低位唯一ID,打破这种可能 要是一个数据中心的时间快了一小时?这会造成这个数据中心的数据始终在更新中占主导,甚至影响了一个小时内的正常的数据更新
COPS使用Lamport钟给v#赋值
每个服务器实现“Lamport钟”或者“逻辑钟”
1 | |
一个新的put,v#就是当前的T, 所以,如果一些服务器的钟快了,其他服务器看到它的版本,就会调快他们的Lamport钟
如果是并发写,简单保留一个,丢掉其他就可以了吗?
这就是论文中的“last-writer-wins”
- 一些情况下没问题,比如,单个写者,没这种情况,可能只有我自己可以改照片和个人信息
- 有些情况很糟糕:要是一堆put()操作操作一个计数器?或者用一个新值更新购物车?
- 这些问题就是“写冲突”(conflicting writes)
- 我们要有更聪明的办法检测和解决
- 真实事务(real transactions)
- 迷你事务(mini-transactions)——原子的increment(),而不是get()/put()
- 对购物车使用自定义的冲突解决(比如合并)
- 如何解决写冲突是最终一致性的问题,没有单个“串行化点”(serialization point)实现原子操作和原子事务
- 论文中大多忽略了写冲突的问题,但真实系统它仍是一个问题
回到最终一致性和稻草人1号: 存储系统可以提供更直觉的结果吗? 从本地读,但从其他数据中心写吗?
稻草人2号
- 提供sync(k, v#)操作
- sync操作直到所有数据中心使k至少达到版本v#
- put(k)时产生v#,然后client再调sync()
- “最终+屏障”
- sync()是慢的:需要和其他数据中心通信,并等待
稻草人2号的clients调用sync,使得读者可以看到数据以实际更新的顺序出现
1 | |
C2可能看不到新list,但是看到新的list时,那么photo也一定是新的
稻草人2号的应用必须消息put()s和get()s的顺序
- 典型的,get()的数据顺序和put()的数据顺序相反
- sync()保证你看到list,那之后一定看到新photo
- sync()也强迫刷新:sync()返回后,读操作可以看到写入的数据
稻草人2号可能非常糟糕
- 它是直接有效的设计
- 如果不需要事务,那语义很棒
- photo和list正常了,即使要求get()顺序和sync的编码
- 读性能很棒
- 写性能也行,如果写操作不多,或者不在乎等待
- 毕竟,Facebook / Memcache的所有写到要发到primary
- Spanner要等待大多数的副本
可以更低成本实现sync的语义吗? 我们可以告诉远程数据中心正确的顺序,而不用等待?
一种可能:每个数据中心有个单点的写log
- 每个数据中心单点的日志服务器(log server)
- put()加到本地的log,但不等待
- no sync()
- log服务器按顺序发送log到其他数据中心
- 远程按顺序应用log
- 所以put(photo), put(list)的更新顺序就对了
- 这不是完整的方案,但也可以实现
- 但是日志服务器可能是瓶颈,因为分片很多,所以COPS不使用这种方案
所以:
- 我们希望异步的推送put(没有sync和等待)
- 我们希望每个分片独立的推送put(没有日志服务器)
- 我们希望按照应用的顺序
每个COPS的client包含“context”,反应client的操作顺序 client每次在get()和put()后都加新item到context client告诉COPS按照context的顺序,put顺序
1 | |
COPS称“Zv3 在 Yv4之后”的关系是一种依赖
- Yv4 -> Zv3
- 这种依赖COPS要做什么?如果C2看到Zv3,在请求Y,那他至少能看到Yv4
- 这种依赖关系更加直觉,以下两种呢?
- get(Y) AND THEN put(Z)
- put(Z) AND THEN put(Q)
每个COPS分片服务器
- 当从client收到put(Z, -, Yv4),
- 给Z,新v#=3
- 保存Z, -, v3
-
发送Z/-/v3/Yv4给每个数据中心对应的分片,但不等待返回
- 远程分片收到Z/-/v3/Yv4
- 和本地分片协调Y,直到Yv4到达
- 然后更新数据库Z/-/v3
关键点: 如果远程数据中心的读者看到Zv3,然后再读Y,那版本至少不晚于Yv4
这样photo list就正常运转了: put(list)依赖于photo的达到,远程服务器在更新list前,要等待photo的送达
这种一致性语义称为“因果一致性”(causal consistency)
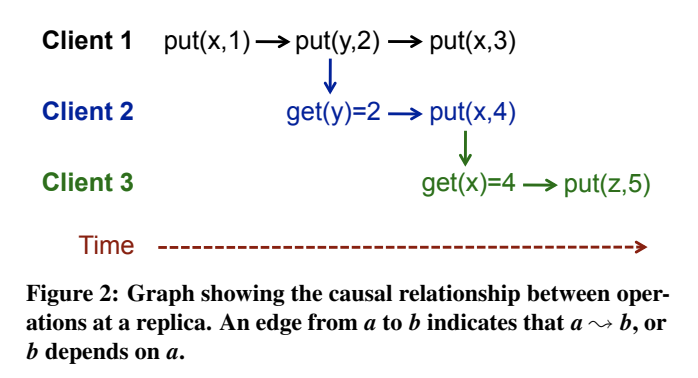
一个client在版本间建立了依赖,两步:
- 它有自己的puts和gets的序列(“执行线程”(Execution Thread),Sec3)
- 读取另一个client写的数据
依赖是可传递的(如果A -> B, B -> C, 那么A -> C), 系统保证,如果A -> B,并且client读到B,那么client再之后能看到A(或者就是之后的版本)
注意:当更新是有因果关系的,那么读者就能看到写者锁看到的顺序。
注意:但更新并没有因果关系,COPS就没有顺序的功能,比如
1 | |
- X必须在Z之前出现(这是COPS的功能)
- Y不必在Z之前出现
这种特性是论文中声明的可扩展性的基础
注意:读者也可能看到比因果依赖要求的数据更新的数据,所以我们不能用事务或者快照
注意:COPS能看到的,只有确定的因果依赖关系 COPS可以从client的get()和put()中观察, 如果有其他通讯渠道,那就只是最终一致性, 比如,我put(k),通过电话告诉你,你使用get(k),可能你不会看到我的数据, COPS并非外部一致性的
避免client contexts的无限增长的优化:
- put(K)->vN发到context,然后清除context,替换为KvN, 下一次put,比如put(L),只依赖于KvN,所以远程在等待L前要等待KvN的到达, KvN本身等待context被清除, 所以L也等待context被清除
- GC看到所有数据中心都有一个版本,这个版本不需要context再记住了,因为大家都看得到
是否有种情况,puts/gets的顺序不足? 论文的例子:photo list,带有ACL(访问控制列表,Access Control List)
- get(ACL),然后get(list)? 在两次get()中,要是有人把你从ACL中删除,又加了张照片?
- get(list),然后get(ACL)? 要是有人删除了照片,再把你加到ACL?
需要多键的(multi-key)get,返回相互的版本
COPS-GT get_trans()的方案
- 服务器保存每个值全部的依赖关系
- 服务器保存一些旧版本号
- get_trans(k1,k2,…):client库和get()无关,get()也返回依赖,value/v#
- client检查依赖
1
2
3for each get() result R, for each other get result S mentioned in R's dependencies,(对一个R,在所有R是否有依赖) is Sv# >= version mentioned in R's dependency? (有依赖,至少版本号要达到R的版本号) - 如果所有都是yes,返回结果
- 否则,需要再来一轮get(),因为值太老了
1 | |
为什么COPS-GET获取事务只需要两个阶段? 一个新值只有在他的依赖被安装才会安装,所以如果get()返回一个依赖,它一定已经在本地被安装了。
性能? 大约每秒50000操作,也还行,和一般数据库一样。
不与其他系统比较:不为了性能、不为了方便编程
很糟,因为COPS的核心理论是对方便编程和性能之间的权衡
限制/缺点(COPS和因果一致性)
- 写冲突是很严重的问题
- client遵循这种因果关系,很尴尬,比如用户或浏览器,访问多个页面,多个服务器
- COPS看不到外部的因果一致性,现实中,软件和人都可能在COPS之外通信
- “事务”含义的限制
- 只有读(提到了点)
- 定义比可串行化事务更加微妙
- 追踪、通信、遵循依赖需要费不小的花销
- 远程服务器必须检测和延迟更新
- 延迟更新可能造成级联的效果
影响?
- 因果一致性是很流行的研究想法
- 好的原因:兼顾性能和好用的一致性
- 在COPS前有很多研究,之后有Eiger, SNOW, Occult
- 因果一致性在生产环境的存储系统很少使用
- 那用的是什么?
- 非地理复制,只是本地
- primary-site(PNUTS, Facebook/Memcache)
- 最终一致性(Dynamo, Cassandra)
- 强一致性(Spanner)